Article Text

Statistics from Altmetric.com
Recent scientific, political, industrial, and public relations efforts to publicise the first interpretations of the human genome sequence raised unprecedented social expectations towards the health sciences1–6; yet, prudence seems warranted when assessing the relevance of emerging genomic knowledge to lessen the burden of illness in human populations.7–9 Among the formidable tasks that lie ahead, it will be important to achieve a proper understanding of how genes and the environment interact to cause human disease.10–14 This aim will partly depend on how molecular epidemiological studies are conducted. Long viewed as a promising approach,15 molecular epidemiology is no longer in its infancy.16–25 Figure 1 shows that the number of studies ascribed to molecular epidemiology increased dramatically during the past decade. Yet, as shown in table 1 and figure 2, “molecular epidemiological” studies are just a fraction of studies attempting to integrate epidemiological, genetic, and molecular dimensions of disease. Even if nowadays some features of molecular epidemiological studies retain some novelty, other basic challenges have always been undisputed.11 Prominently, the need to integrate valid biological, clinical, and epidemiological information from unbiasedly selected populations. Indeed, tumour tissue procurement and, more generally, the availability of biological samples are crucial in molecular epidemiology. However, although completeness of the “biological study base” is frequently hampered by ethical, clinical, and logistic factors, these are rarely analysed in depth. Unaccountably, molecular epidemiological studies often fail to properly assess whether selection biases affect their results.26 Exceptions do exist, of course. One is the study by Slattery et al—interestingly, published in Mutation Research Genomics.27 The authors were able to collect blocks and extract DNA for 2117 of 2477 people (86%) for whom they had permission to obtain tumour blocks. They found no differences in age, tumour site, or diet and lifestyle characteristics between subjects with and without DNA extracted. However, they were less likely to be able to extract DNA if the case was diagnosed at a more advanced disease stage or at the earliest stage.
Number of articles (“items”) listed in PubMed with the terms “epidemiology, molecular” (MeSH term) (column A), “epidemiology” and “molecular” (any field) (column B), and “epidemiology” and “gene*” (any field) (column C)
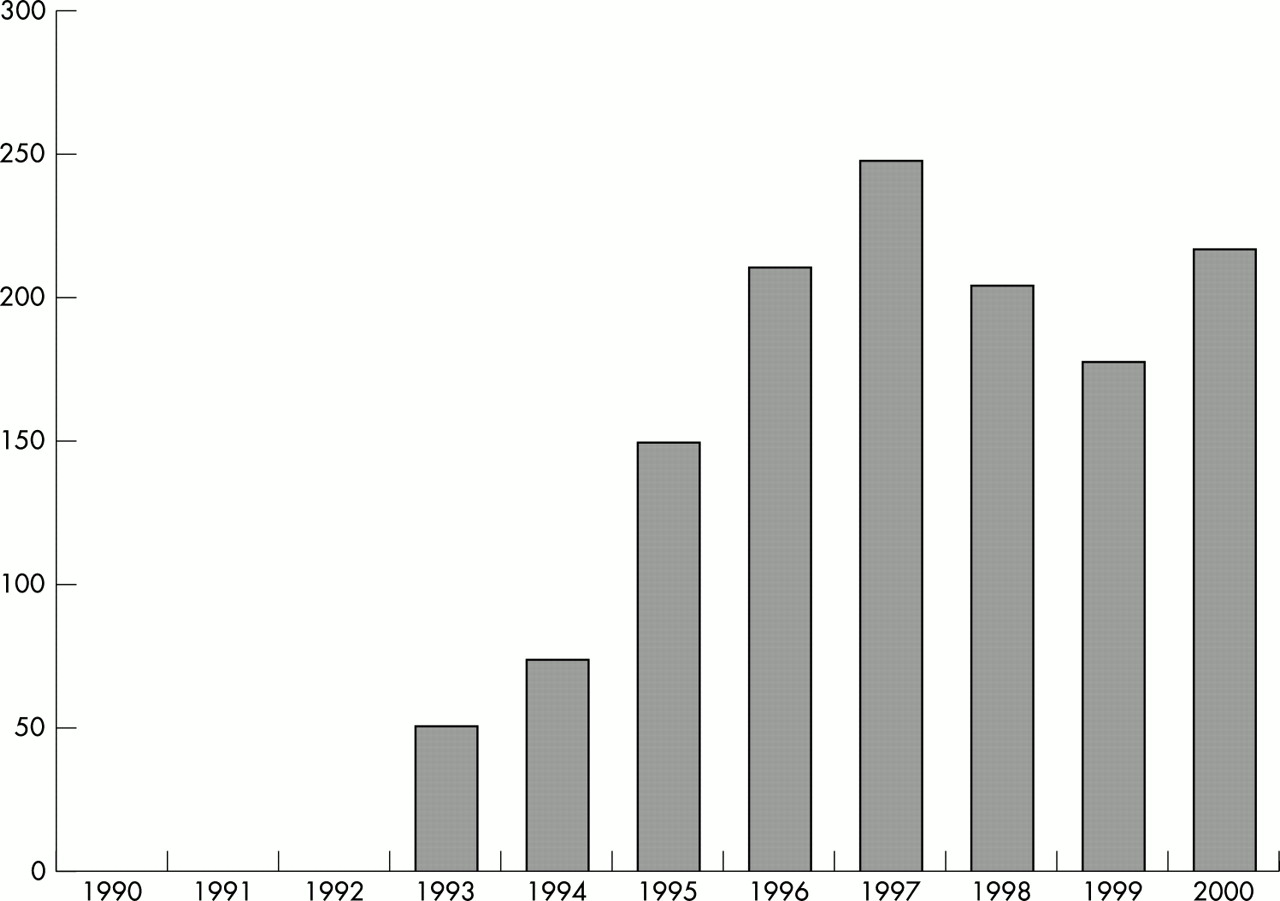
Number of articles from “molecular epidemiological” studies (column A of the table).

{kind=link}
{kind=link}
Number of articles with the terms mentioned in columns A, B, and C of the table.
INCOMPLETE OVERLAPPING OF BIOLOGICAL, CLINICAL, AND ENVIRONMENTAL INFORMATION: AN EXAMPLE
Studies providing opportunities to think about the consequences of an incomplete overlapping of biological, clinical, and environmental information abound.26,28,29 Of course, they include our own, where we have often tried to control the problem—not always successfully—and to discuss such consequences.26,30–35 Another recent example is the case-case study by Slebos et al.36 It investigated whether in pancreatic cancer alterations in the K-ras and p53 genes may be related with aspects of the patients’ medical history, the histopathology of tumours, and environmental exposures. The study deserves to be commended on a number of strengths, including the use of advanced techniques for the molecular analyses of pure populations of tumour cells, the attempt to account for subjects that could not be included in genetic and organochlorine compounds analyses, and the cautious conceptualisation of the results. Such strengths notwithstanding, the study has potentially important limitations. The causes and consequences of such weaknesses merit analysis for two main reasons: firstly, because some of the study conclusions might be erroneous; and secondly, of even broader interest, because the limitations may illustrate some potential pitfalls of molecular epidemiological research.
This debate concerns many scholars who work on molecular epidemiology, and very directly those who study pancreatic cancer and other cancers whose diagnosis is especially difficult. To broadly contextualise the debate, the following facts are worth noting: over 12 years after their high prevalence at diagnosis was first reported, point mutations in the K-ras gene remain the most consistent genetic alteration in exocrine pancreatic cancer. Even more important, K-ras mutations are one of the most common genetic alterations in human cancers—probably, the most frequent somatic (acquired) oncogene mutation.37 It is hence puzzling that so little evidence is available for or against the hypothesis that the occurrence and persistence of K-ras mutations may be related to environmental factors. Let us then synthesise the main limitations of the study by Slebos et al, and analyse their potential effects upon their conclusions.
-
Out of some 611,38 “more than 550”,36 or 374 (321+53) 36 eligible patients, 61 (16%), 49 (13%), and 24 (6%) were integrated in the analyses of K-ras, p53 and organochlorine compounds, respectively (percentages are for 374). Because the percentage of patients potentially eligible for inclusion who were finally analysed is low by conventional epidemiological standards, it seems pertinent to ask why. A possible explanation regards the fact that about 55% 38 or more 36 of cases were deceased when contacted. This possibility should make us think about methods we use to identify eligible patients, and about practical ways to shorten the distance between the clinicians who diagnose cases and the epidemiologists-researchers. It is also possible that the low percentage of cases analysed was partly attributable to the fact that about two thirds of patients without surgical tumour material were excluded.36 If so, maybe the authors should have kept in mind the possibility of retrieving cytohistological samples from fine needle aspiration and endoscopic or laparoscopic procedures, which most patients undergo,39 and which permit efficient analyses of K-ras and p53. The evolution of diagnostic technologies and clinical algorithms is a permanent challenge to researchers trying to minimise selection biases. It deserves similar attention than laboratory techniques suitable for population studies.20,26,33,40–42 We are aware that the description of the process followed to select cases is at other times much less comprehensive28,29 than in the article by Slebos et al.36 We have also experienced the difficulties that these issues present when due respect is given to ethical and clinical matters.26,30,31,43 In the PANKRAS II Study, for example, we analysed K-ras in 121 of 185 potential subjects (65%).32 Both K-ras and organochlorine compounds were initially assessed in 51 (27%) patients 33; this was largely by design, as it was a pioneer study. We also provided a detailed comparison of the 51 patients included and the 134 patients initially excluded.34 Modest steps, admittedly, but in the right direction.
-
Slebos et al provided an interesting comparison of some characteristics of patients included (as their tumour blocks were available, n=61)36 and of patients included only in the original case-control study based on cases selected from the San Francisco Bay Area (n=321).38 It is unclear, however, how many of the 61 cases originated from the 321 cases, as some of the 61 patients came from 53 additional cases later retrieved from the University of California at San Francisco (UCSF) pathology records. It is also unclear if the latter cases were interviewed in a similar way as the former.36 It would also have helped (to assess the validity of results on organochlorine compounds) that the authors had provided data on their respective times of blood sampling (which apparently occurred about three months after diagnosis in the original study).38 These issues concern a large number of molecular epidemiological studies that tend to use patients from a variety of clinical settings in order to palliate the low number of cases with biological samples available to researchers.
-
It would have been useful for Slebos et al to compare several other characteristics of cases included and excluded; prominently, tumour stage at diagnosis (or at the time of blood extraction, if available). Staging information is essential in any molecular epidemiological study of clinically aggressive diseases as pancreatic cancer. It is even more important when studying organochlorine compounds because lipid mobilisation (which might spuriously increase serum organochlorine concentrations) is more likely with increasing cancer dissemination.44 We are not aware of scientific evidence supporting the claim 38 that lipid levels may “stabilise” after a diagnosis of pancreatic cancer. We suggest it might also be of interest to have data on treatments given before blood sampling (because some might change serum organochlorine concentrations), changes in BMI (or weight loss), symptoms before blood collection, and lipid concentrations for the subsets of patients included and excluded from the original 38 and the new study.36
-
The comparison of characteristics could have been extended to the 49 and the 24 cases available, respectively, for p53 and organochlorine compounds analyses, as main conclusions of the study are based on the latter two groups. Briefly, the point is: while the attempts to describe subjects that could not be included in genetic and environmental analyses made by Slebos et al,36 Slattery et al,27 and ourselves are praiseworthy, the descriptions are often incomplete. The fact that most other studies do worse is of little comfort.26,30
Can the previous problems on selection and information bias be of any consequence? The next set of issues suggests that they can.
In pancreatic cancer, tumour stage at diagnosis has consistently been found to be unrelated to K-ras mutation status by the larger studies.30,45–47 It is hence worth thinking why in the study by Slebos et al the 15 K-ras wild-type patients had more localised tumours than the 46 patients with K-ras mutations36: the former were over three times more likely to have stage I tumours than the latter (OR = 3.86, 95% CI: 1.02 to 14.62). We see no clear explanation for this association. Perhaps a selection bias occurred, probably because of the small number of subjects. As said, the issue is also interesting because it may illustrate the cascade of consequences that selection bias may have for causal estimation. In this instance, the consequences may have been threefold.
-
The authors found 36 that diabetes was more common among patients with wild type K-ras (six cases) than among patients with K-ras mutations (two cases). The finding was never reported before. But pancreatic cancer may be diagnosed at earlier stages in people with diabetes,48,49 possibly because they are under closer medical supervision than non-diabetics. Therefore, a possible explanation for the finding is simply that wild type cases had (by chance) a more localised distribution of stage.
-
It is possible that some organochlorine compounds may increase the risk of diabetes.50–54 If so, the overrepresentation of diabetics among the seven K-ras wild type cases would tend to mask differences in organochlorine compounds concentrations with the 17 mutated cases. This might partly explain differences with a previous study of ours: we found that mutated cases had significantly higher concentrations of organochlorines than non-mutated cases.33
-
The 46 subjects with a K-ras mutated tumour were almost three times more likely to be in the upper category of total coffee consumption than the 15 cases without a mutation (OR=2.78, p=0.11) (incidentally, the p value of 1.00 that the authors offer is wrong; the p value published for caffeinated coffee is also overestimated, while that for decaffeinated coffee is correct).36 But polyuria (frequent secretion of urine) and polydipsia (frequent thirst) are common symptoms of diabetes: increased urination is a consequence of osmotic diuresis secondary to sustained hyperglycaemia; this results in a loss of glucose as well as free water and electrolytes in the urine. Thirst is a consequence of the hiperosmolar state.55 It is thus plausible that the diabetic patients included in the study had a tendency to drink more liquids than non-diabetics. If so, a spuriously high presence of diabetics in the wild type group may have blurred case-case differences on coffee consumption. A slight bias in the direction we hypothesise would bring their OR closer to the figure of 3.65 that we observed based on 83 mutated and 24 wild type cases, as discussed in this journal.32,56 Should the study by Slebos et al be thought to provide fresh additional evidence for an association between coffee consumption and K-ras mutations in exocrine pancreatic cancer? One could be inclined to think so, but the first set of questions we posed above makes the judgement uncertain. And so we may be unable to assess another potentially important gene-environment interaction.
MOLECULAR EPIDEMIOLOGY CAN DO BETTER
More needs to be known about the environmental aetiology of cancer and the causes of genetic alterations in this and other groups of diseases.11–14,16,19–21,24 But such knowledge is proving elusive. Perhaps for lack of appropriate studies? (For example, for lack of valid studies that care to assess oncogene-environment interactions?). Research funding is at a historical high in the United States, the nation that leads international research on cancer. The study by Slebos et al is only the second attempt to analyse internal concentrations of organochlorine compounds and K-ras mutations in any human cancer. Beyond the merits and limitations of this and other studies, all this reflects the difficulties faced by most of us worldwide, and the limitations of some research approaches to the causes of complex diseases. An open debate on these issues should help to design, conduct, and analyse more valid and meaningful molecular epidemiological studies. It would hence help to add value to research on human genomics—modestly, but distinctly.
Acknowledgments
Thanks are due to J M Corominas, A Salas, L Guarner, J Rifà, S Coll, R Solà, and M Andreu for scientific advice; to D J MacFarlane, E Fernandez, J L Piñol, S Costafreda, G Castañeda, J Ngo, and A Serrat for technical assistance; to A Amorós for help in drawing the figures; and to P Barbas, L Español, and O Juan for secretarial assistance.
REFERENCES
Footnotes
-
Funding: partly funded by research grants from Ministerio de Ciencia y Tecnología (CICYT SAF 2000–0097), Fondo de Investigación Sanitaria (95/0017) and Generalitat de Catalunya (BEAi 1998/400011 and DURSI 2001/SGR/406).
-
Conflicts of interest: none.