Article Text

Abstract
Systems models, which by design aim to capture multi-level complexity, are a natural choice of tool for bridging the divide between social epidemiology and causal inference. In this commentary, we discuss the potential uses of complex systems models for improving our understanding of quantitative causal effects in social epidemiology. To put systems models in context, we will describe how this approach could be used to optimise the distribution of COVID-19 response resources to minimise social inequalities during and after the pandemic.
- Disease modelling
- Epidemiological methods
- Epidemiology
- Social epidemiology
This article is made freely available for use in accordance with BMJ's website terms and conditions for the duration of the COVID-19 pandemic or until otherwise determined by BMJ. You may use, download and print the article for any lawful, non-commercial purpose (including text and data mining) provided that all copyright notices and trade marks are retained.
Statistics from Altmetric.com
INTRODUCTION
The health and well-being of the public are determined by complex interactions between biological, individual, societal and environmental factors.1 These often intertwine in dynamic and context-specific ways that can make studying any one component in isolation misleading or limiting. Feedback loops; leverage, tipping points or other non-linear relationships; interference, transmission, or spillover; and emergent properties such as social organisation can make traditional regression-based analyses of observational, or even randomised trial, data insufficient for understanding the causes and determinants of public health.2–9 Social epidemiology has long grappled with this complexity and emphasises the need for formulating and formalising a clear theoretical framework before attempting to untangle these forces.1 10 Agent-based models or compartmental models have been proposed as a solution for understanding complex systems in social epidemiology.4–6 11 12
In this paper, we review the use of these systems models in social epidemiology and link them to quantitative estimation of causal effects under the potential outcomes framework in the hopes of further advancing the use of complex systems methods in social epidemiology.
Brief introduction to complex systems models
Complex systems are those with a large number of interacting components.5 Complex systems models encompass a broad range of methodologies that generally use computational simulation of relationships between features in a pre-specified structure to understand the ways in which these features interact. In the context of public health, two major classes of models are of particular interest: group-level and unit-level systems models.
Group-level models include infectious disease transmission models such as SIR and SEIR models; health policy models, such as Markov cohort models; and compartmental models of disease progression. The common feature of these models is that they simulate the evolution of the point prevalence of one or more conditions of interest within groups or strata of individuals. For example, in an SIR model, the strata of interest are ‘Susceptible’, ‘Infectious’, and ‘Recovered’, whereas in a policy model, strata of interest might include ‘Symptomatic’, ‘Diagnosed’, and ‘Connected to Care’. These strata are often referred to as ‘states’. Group-level models can be dynamic or static. In dynamic models, such as the SIR model, the number of people within a given state at a particular time point influences the rate of movement through the system of individuals in other states. In static models, such as a Markov cohort model, the rate of movement through the system depends only on an individual’s current state (possibly including an indicator for some key features such as age or gender), but not on the current states of other individuals. Group-level models have the advantage of being relatively low complexity and requiring minimal computational resources—indeed they can generally be solved numerically without simulation. However, the trade-off for computational simplicity is that these models can be challenging to design and parameterise. Limiting the number of states requires strong assumptions about which strata are meaningful to include and what factors govern the rate of progression between strata,13 and determining appropriate values for these progression rates can be challenging especially when the population of interest has not been well-studied.
Unit-level models include agent-based models (often called ‘ABMs’) and individual-level simulation models (also called microsimulation models).14–16 The defining feature of these models is that each simulated unit represents a single individual in a (virtual) population, as opposed to a group of individuals as modelled in the group-level models. The chief benefit of simulating individuals rather than groups is the ability to track and include aspects of an individual’s personal history, location in space and time relative to other individuals, and interactions between individuals. The main difference between agent-based models and individual-level simulation models is whether the individual units are simulated in isolation from each other (individual-level models), or whether units can transmit information (eg, education or infection) between one another (agent-based models); although this distinction is not always consistently defined in the literature.14 This transmission allows for the possibility of interference, also called spillover or dependent happenings, which occurs when the outcomes of one or more individuals in the population affect the exposure and/or outcome of other individuals.17–19 In addition to the interaction between agents, agent-based models can consider heterogeneity, or differences, among agents and types of agents within an environment. Heterogeneity is necessary to represent the complex populations that exist in the real-world and is incorporated by including in the agent-based model the types of actors that may exist in a system. Heterogeneity can be modelled at the exposure, outcome, covariate, or probability levels.19
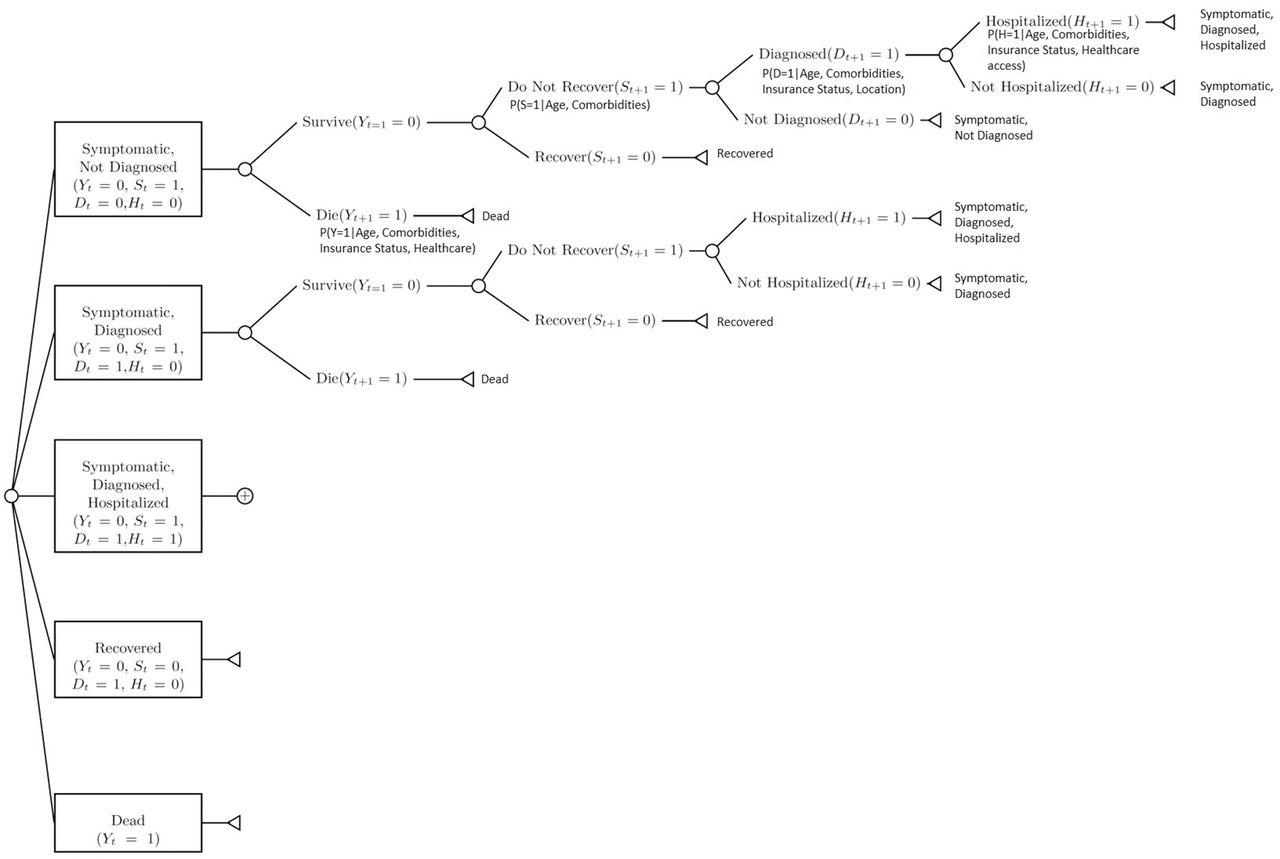
Complex systems models are designed to represent key states, characteristics, or decisions that individuals or groups pass through over time. One common way of visualising the structure of a systems model is to create a decision-tree that depicts the relevant variables, the possible pathways, and the potential downstream consequences for an agent in the simulation. This structure can be used to depict both group-level and individual-level systems models, although group-level models are often more commonly depicted with compartment or flow diagrams. For simple systems models, the decision tree can also be used to run the simulation.20
Figure 1 depicts a possible systems model for COVID-19 using the decision-tree framework. This tree describes five possible states at any given time for an individual with COVID-19: (1) currently symptomatic, but not yet diagnosed or hospitalised; (2) currently symptomatic and diagnosed, but not yet hospitalised; (3) currently symptomatic, diagnosed and hospitalised; (4) recovered; and (5) dead. In order to evaluate the impact of social factors on the progression of individuals between these states, the decision tree allows the probability of transitioning between these states to depend on the individual’s underlying health status, insurance status and access to testing.

Decision tree for a systems model evaluating the role of access to testing on COVID-19 morbidity and mortality. Testing access in the model is represented in the conditional probability of diagnosis given age, comorbidities, insurance status, and location. Letters represent variables and subscripts represent time-point and are included to allow the reader to gain intuition about how individuals move through the system: Y is vital status (0=alive, 1=dead); S is symptom status (0=no symptoms; 1= symptoms); H is hospital status (0=not hospitalised; 1=hospitalised); D is diagnostic status (0=not diagnosed, 1=diagnosed).

{kind=link}
{kind=link}
Causal directed acyclic graph for the relationships between individual and neighbourhood characteristics, SARS-CoV-2 testing, and COVID-19 morbidity and mortality.
Social epidemiologic example: inequity and COVID-19
To put systems models in context, we use an example based on COVID-19 and related social inequalities that both exacerbate and are exacerbated by the 2020 pandemic (figure 2). Recent COVID-19 research has found large disparities in COVID-19 morbidity and mortality between minoritized and majority communities around the world.21–24 The relationship between social epidemiology and infectious disease is a well-established one,1 25–27 and many of the complexities encountered in social epidemiology have been studied in the infectious disease context. We hope to provide social epidemiologists with a toolkit to both understand the growing number of COVID-19 models and apply those modelling skills to other important social epidemiologic questions by using COVID-19 as an example.
A substantial body of literature exists highlighting the disproportionate impact of COVID-19 on People of Colour including Black and Indigenous communities, both internationally28 29 and across the United States.30–32 In the US, Black and Indigenous communities have been particularly negatively affected by COVID-19 compared to non-Hispanic whites,30–40 with exacerbated disparities at the intersection of age and race/ethnicity.34 41–45
Although some have argued that variation in underlying health status is to blame,46 it is more likely the disparities in both health status and COVID-19 stem from wide-spread structural problems, including systemic and structural racism; racial capitalism, in which racial oppression is crucial for the accumulation of capital rooted in American culture,47 and medical racism, in which minoritized individuals receive lower quality care and experience greater delays and barriers to accessing healthcare.48–60
For example, in the US racial and ethnic minorities make up a significant proportion of essential workers who cannot work from home57 and often rely heavily on public transportation.58 These factors put them at greater risk for acquiring the virus than those who can quarantine completely. Furthermore, 25% of the essential workers in the US live in low-income households, and 18% have at least one uninsured household member.59 The differences in the allocation of public health infrastructure and resources create vulnerable communities that may not be well-supported to deal with the pandemic.60–65
For the remainder of this article, we explore how complex systems models could aid in answering the social epidemiologic question: ‘How can we best distribute limited COVID-19 testing resources in order to minimise social inequities?’
DESIGNING SYSTEMS MODELS FOR CAUSAL INFERENCE
Systems models have long been used to generate hypotheses about possible causal relationships, triangulate information on potential mechanisms, and identify potentially important leverage points.66 When our question of interest requires a quantitative estimate of a causal effect for decision making, systems models can also be useful but need to be defined to clearly and carefully specify the causal assumptions. The use of quantitative methods for estimating causal effects in social epidemiology has been the subject of much, sometimes heated, debate.10 67–80 However, many of these debates revolve around the problem of specifying sufficiently complex causal questions to capture many levels at which social determinants of health operate. We argue that systems models, which by design aim to capture multi-level complexity, are in fact the natural choice of tool for bridging the divide between these two sub-disciplines, especially as the use of these models for estimating counterfactual outcomes is becoming more formalised.6 9 81–84
The key feature of designing systems models for quantitative causal effect estimation is to design the model with a clear set of causal assumptions. The required assumptions are similar to those required for any causal effect estimation using randomised trials or observational data,81 with the additional caveat that we must now be sure to design and parameterise our model correctly, not just measure and adjust appropriately. We briefly review the required causal assumptions for traditional methods and describe special considerations for systems models.
The first assumption is the Stable Unit Treatment Value Assumption, or SUTVA. This assumption can roughly be decomposed into two components: consistency and no interference.
Consistency requires that the counterfactual world we think we are making inference about is the one we are actually making inference about. In practice, this is typically supported by the need for a clear causal question, reflecting a comparison between two or more interventions or exposure states applied to a specific group of individuals,85 although the appropriate formulation of these questions in social epidemiology has been questioned.86 In the context of a complex system, observational data and/or randomised trials are often unlikely to be sufficient to establish consistency since the data requirements for unravelling complexity increase rapidly. In contrast, complex systems models can allow us to be more creative in our specification of causal contrasts, more easily apply multi-level interventions, and assess multi-level outcomes. Creating and using a systems model requires clearly specifying a framework under which key characteristics are related, and an algorithm by which the desired contrasting exposure levels can be obtained. Although these may not always clearly represent real-world policies, the algorithm must be detailed enough for the computer (and by extension the researcher) to thoroughly understand the counterfactual scenarios of interest. This detailed algorithm provides a specification for the meaning of the counterfactuals we aim to compare—that is, it allows us to assume that our results are at minimum consistent for the exposure contrast we have specified in the simulated world which the model represents.
For example, if we are interested in understanding whether a COVID testing strategy based on prioritising individuals in high-incidence neighbourhoods helps to reduce racial and ethnic disparities in COVID-19 hospitalisation, using observational or trial data may be difficult due to the complex interplay between structural racism, COVID risk and vulnerability, residential neighbourhood, and healthcare access. In a complex systems model, we explicitly describe how we believe these relationships work, and then assess the impact of our testing strategy conditional on our assumptions about the model structure and rules.
SUTVA also relies on the assumption of no interference—that is, that the exposures and outcomes of two or more individuals are independent of one another. By nature, many of the questions of interest that are assessed using systems models explicitly violate this assumption. However, there is a growing body of work that describes how to estimate causal effects in the presence of interference,17 18 87 88 and these can be extended to complex systems models.89
The second key assumption of causal inference is positivity; all individuals in our population must have some probability of being in either group—no individual can be a ‘never treat’ or ‘always treat’ without a clear rule specifying this behaviour in the model. This can be difficult to achieve in observational data, but is built into the creation of systems models—all individuals must have a pre-specified probability of receiving an exposure, and researchers can assess the model to ensure there are no groups for which exposure will always or never be assigned. The requirement for positivity is a challenge for the use of the potential outcomes framework in social epidemiology—under this framework we can only estimate causal effects when data exist and exposures are possible. However, the use of complex systems models can allow us to somewhat relax this assumption by changing the rules of our simulated model universe to change the probability of exposure in a group for which exposure is actually always or never available. Note however that this requires strong assumptions about the impact of exposure in this group that may be difficult or impossible to justify.
The third key assumption is that of exchangeability—that is, the counterfactual distributions (and thus the distribution of covariates that cause confounding) for individuals who are in the exposed or treated group must be the same as those in the reference category.90 91 These assumptions require being clear about the population of interest, and understanding all shared causes of our exposure and outcome of interest. In observational studies, exchangeability is supported via the collection of rich covariate data to ensure all confounding paths between exposure and outcome can be blocked.90 The same principle can be applied to systems models with a slight modification: we must model all covariates necessary to ensure that all confounding paths between all pairs of variables already in the systems model can be blocked.81 In addition, systems models require the additional assumption that the parameter inputs used to build the model are estimates of causal effects and were obtained from populations where these effects have the same value as in the population of interest.81 82 This last assumption amounts to requiring the causal inference assumptions for every pair of variables in the systems model, and is often the most challenging to establish.82
One useful way of clarifying the above assumptions when designing a systems model is to employ the Target Trial Framework.92–94 This framework asks the researcher to detail the protocol of an ideal (and sometimes unrealistic) randomised trial for the research question of interest. This helps define the specific features of the population, the specific comparison of two or more intervention or exposure groups, and the outcome(s) measurements of interest. This protocol then serves as the base on which to build a model, and allows other researchers to more easily assess whether they believe the assumptions required are sufficient to interpret the results causally.
Target trials in the presence of interference
An important consideration for systems models is that the ideal trial for many of the questions of interest would be one that asks complex questions such as ‘how do we best distribute limited testing supplies to minimise social inequalities?’. Questions such as this involve understanding that resources, information and exposure are shared between individuals, but their complexity does not prevent us from evaluating them using systems models, nor does it prevent us from specifying clearly defined, although complex, causal questions. For example, in the setting of SARS-CoV-2 testing, when a test is used on one individual it cannot be used on another individual. This problem can lead to challenges with the consistency assumption unless the causal question is specified in a way that accounts for the concepts of interference, transmission, spillover, or dependent happenings.
Fortunately, there are many existing solutions for how to ask complex causal questions under these settings. For example, complex trial designs have been developed which can allow researchers to answer these questions, including cluster-randomised, network-randomised, and ring vaccination trials.17 87 95 In addition, the recently developed auto-g-computation algorithm could be extended to improving causal effect estimation with ABMs when the no interference assumption is violated.96 Systems models can be designed to incorporate transmission of information (disease or resources) between individuals, and emulate the results of these more complex randomised trials to obtain an estimate of the causal effect under transmission scenarios.84 These models are commonly used in infectious disease epidemiology where researchers can model outbreaks and the spread of disease due to the interaction between agents. This is especially relevant for COVID-19 models, and numerous research groups have already released models describing the extent and duration of the pandemic based on varying transmission assumptions.97 98 But agent-based models can also be a valuable tool for understanding social epidemiologic questions. There are many features of the social environment, which transmit between individuals (eg, education, or violence), and many ways in which the outcomes or exposures of one individual can affect the exposure or outcome of another individual.
As an example, let’s revisit our decision-tree model depicted in figure 1. There, we allowed the availability of tests to influence the probability that an individual with COVID19 symptoms would be diagnosed. If our population of interest has access to only a fixed amount of tests over time, then we can incorporate this into our model by allowing the probability of testing to decrease over time, or by explicitly modelling the availability of tests—decreasing the number of tests as they are used, and increasing them when new supply is available. This second approach would require building an additional layer into our model that simulates the supply of tests over time. If relevant, a third layer could be added with information on location of tests or individuals to allow test access to vary over space as well as time.
We provide a step-by-step guide on how to build asystems model to answer our research question ‘How can we best distribute limited COVID-19 testing resources in order to minimise social inequities?’ in the online appendix. The first step to creating a systems model is to define a clear research question of interest, including a well-specified population, exposure and reference groups, time period and location information, and a well-defined outcome of interest. The next step is to use the target trial framework to design a hypothetical trial protocol to answer the research question. Step 3 entails specifying variables and assumptions that will govern how agents interact and move through time/space, including potential confounders, colliders, mediators or effect modifiers. After this information has been agreed upon, the next step (Step 4) is to build the model to answer the research questions (from Step 1) using the trial protocol created in Step 2. Finally, Step 5 is to design and run additional analyses to test the accuracy and estimate the uncertainty of the model online appendix. At all steps when building a systems model, it is important to keep in mind the parameters and rules to ensure a good fit.
Supplemental material
CONCLUSION
Systems models are a valuable tool for understanding the complexity of public health as it relates to societal factors and distribution of disease.6 15 16 19 These models provide us with a tool for assessing relationships between multi-level features, including both individual, community and societal factors. Importantly, other methods, such as DAG-based regression modelling, can and should also tackle these issues when data exist or can be directly collected. The chief benefit of systems models is that they can be used in the absence of a complete or rich dataset on the specific target population of interest. Recently, methodological developments have increased the ease with which these models can be designed and implemented when estimation of causal effects is of interest. With this commentary, we hope to provide readers with an overview of how these recent developments work and can be applied to sociological questions.
We presented an example of a model assessing a social epidemiological question about COVID-19 mortality: how do we best distribute SARS-CoV-2 test access in order to minimise social inequities. This question could be further refined to require that we not only identify the lowest disparities based on race and ethnicity but also by other demographic variables—including age, gender, disability status or employment type. The model we discussed focussed only on identifying and treating those who were already ill with COVID-19, but it could also be extended to consider the transmission of SARS-CoV-2 between individuals, or account for geographical variations in transmission, access to care, or access to testing resources.
Systems models are being increasingly used for social and chronic disease epidemiology, and their use entails many benefits to the researcher. Unlike observational data analyses, systems models can be increased in complexity with relatively little additional data requirements. However, these lower data requirements come at the cost of requiring more assumptions in order to imbue the resulting numeric answer with a meaningful causal interpretation. It is important that researchers are clear and explicit about the assumptions they are making when designing and using these models. The target trial framework, coupled with the use of causal directed acyclic graphs, provides a relatively simple toolkit for specifying these assumptions and providing reproducible and reliable answers from systems models.
REFERENCES
Footnotes
Twitter Eleanor Murray @epiellie, Hiba Kouser @h_kouser and Ruby Barnard-Mayers @rubymaei.
Acknowledgements This project was supported by the NICHD (R21HD098733).
Contributors All authors contributed to the conceptualization and drafting of the manuscript.
Funding The authors have not declared a specific grant for this research from any funding agency in the public, commercial or not-for-profit sectors.
Competing interests None declared.
Patient consent for publication Not required.
Provenance and peer review Commissioned; externally peer reviewed.
Data availability statement Data sharing not applicable as no datasets generated and/or analysed for this study.
Supplemental material This content has been supplied by the author(s). It has not been vetted by BMJ Publishing Group Limited (BMJ) and may not have been peer-reviewed. Any opinions or recommendations discussed are solely those of the author(s) and are not endorsed by BMJ. BMJ disclaims all liability and responsibility arising from any reliance placed on the content. Where the content includes any translated material, BMJ does not warrant the accuracy and reliability of the translations (including but not limited to local regulations, clinical guidelines, terminology, drug names and drug dosages), and is not responsible for any error and/or omissions arising from translation and adaptation or otherwise.