Article Text

Abstract
Background Depression is associated with socioeconomic disadvantage. However, whether and how depression exerts a causal effect on employment remains unclear. We used Mendelian randomisation (MR) to investigate whether depression affects employment and related outcomes in the UK Biobank dataset.
Methods We selected 227 242 working-age participants (40–64 in men, 40–59 years for women) of white British ethnicity/ancestry with suitable genetic data in the UK Biobank study. We used 30 independent genetic variants associated with depression as instruments. We conducted observational and two-sample MR analyses. Outcomes were employment status (employed vs not, and employed vs sickness/disability, unemployment, retirement or caring for home/family); weekly hours worked (among employed); Townsend Deprivation Index; highest educational attainment; and household income.
Results People who had experienced depression had higher odds of non-employment, sickness/disability, unemployment, caring for home/family and early retirement. Depression was associated with reduced weekly hours worked, lower household income and lower educational attainment, and increased deprivation. MR analyses suggested depression liability caused increased non-employment (OR 1.16, 95% CI 1.06 to 1.26) and sickness/disability (OR 1.56, 95% CI 1.34 to 1.82), but was not causal for caring for home/family, early retirement or unemployment. There was little evidence from MR that depression affected weekly hours worked, educational attainment, household income or deprivation.
Conclusions Depression liability appears to cause increased non-employment, particularly by increasing disability. There was little evidence of depression affecting early retirement, hours worked or household income, but power was low. Effective treatment of depression might have important economic benefits to individuals and society.
- Keywords
Data availability statement
Data may be obtained from a third party and are not publicly available. Access to the dataset upon which this study is based must be sought from UK Biobank. The code used in the study analyses is available upon request from the authors.
This is an open access article distributed in accordance with the Creative Commons Attribution 4.0 Unported (CC BY 4.0) license, which permits others to copy, redistribute, remix, transform and build upon this work for any purpose, provided the original work is properly cited, a link to the licence is given, and indication of whether changes were made. See: https://creativecommons.org/licenses/by/4.0/.
Statistics from Altmetric.com
Introduction
Depression is a leading cause of disability, estimated to affect 300 million people worldwide, and to have increased in prevalence by 18% in the decade to 2015.1 Due to its prevalence and debilitating nature, understanding the relationship between depression and adverse socioeconomic outcomes has important policy implications for the allocation of government resources.
Associations between socioeconomic disadvantage and depression have long been observed.2 The extent to which these represent causal impacts of depression on socioeconomic disadvantage (referred to as health selection) is unclear. Alternative explanations include socioeconomic disadvantage causing depression (social causation) and confounding factors causing both depression and socioeconomic disadvantage (indirect selection).3–7 Disentangling the contributions of these explanations to observed associations is difficult.3 4 Confounding can be challenging to address, given the difficulty of accurately measuring socioeconomic variables across the life course.
Mendelian randomisation (MR) is an instrumental variable approach which estimates an exposure’s effect on outcomes using exposure-associated genetic variants as instrumental variables.8 This differentiates MR from observational analyses which rely on assumptions of no unmeasured confounding of the exposure–outcome relationship. Instead, MR relies on an assumption of no unmeasured confounding of the genetic variant–outcome relationship. Use of genetic instruments mitigates reverse causation concerns. MR estimates the causal effect of a lifelong tendency to an exposure, rather than short-term effects.9
We employed two-sample MR to investigate the health selection hypothesis. We estimated the effect of depression liability on employment outcomes (non-employment, sickness/disability, early retirement, caring for home/family and unemployment) and on socioeconomic outcomes (household income, hours worked (among the employed), educational attainment and area-based deprivation) in the UK Biobank dataset. We tested for sex differences in all effects. We compared the MR estimates to multivariable adjusted regression estimated associations of depression and outcomes.
Methods
Study population
The UK Biobank study collected data on half a million individuals aged 40–69 from across mainland Britain (2006–2010).10 Participants were excluded from the current study if (1) they were not of working age (ie, above retirement age at assessment time: 60 years for women, 65 years for men); (2) they self-reported ethnicity other than white British; (3) their genetically determined ancestry did not match their self-report; (4) they had withdrawn from the study; (5) they were overly genetically related; (6) there were issues with their genetic data; or (7) they were missing all investigated outcomes. Exclusions are detailed in sections 1 and 2 and in the Strengthening the Reporting of Observational Studies in Epidemiology (STROBE) flowchart (online supplemental figure S1).
Supplemental material

Scatter plot of sick/disabled–SNP associations versus exposure–SNP associations. X axis includes depression–SNP regression coefficient estimates from Howard and colleagues11; Y axis includes sick/disabled–SNP log odds from UK Biobank regressions. Also plotted are the fits for several causal effect estimation methods. MR, Mendelian randomisation; RAPS, Robust Adjusted Profile Score; SNP, single-nucleotide polymorphism.
Depression single-nucleotide polymorphisms (SNPs)
A recent genome-wide association study reported SNPs associated with depression.11 From the authors we obtained association results excluding the UK Biobank cohort (ie, based on the Psychiatric Genomics Consortium and 23andMe cohorts alone). From these we identified associated SNPs (p value ≤5×10−8). SNPs were excluded based on the Hardy-Weinberg equilibrium (family-wise error rate <1), information content (info score <0.9), minor allele frequency (MAF <0.01) and being palindromic with a high MAF (MAF >0.4). Clumping of remaining SNPs (Physical distance threshold for clumping=10000 kb, R2=0.01), yielded a subset of 30 independent associated SNPs, our instrument SNP set. For further details, see section 2 and online supplemental figure S2 and table S11.

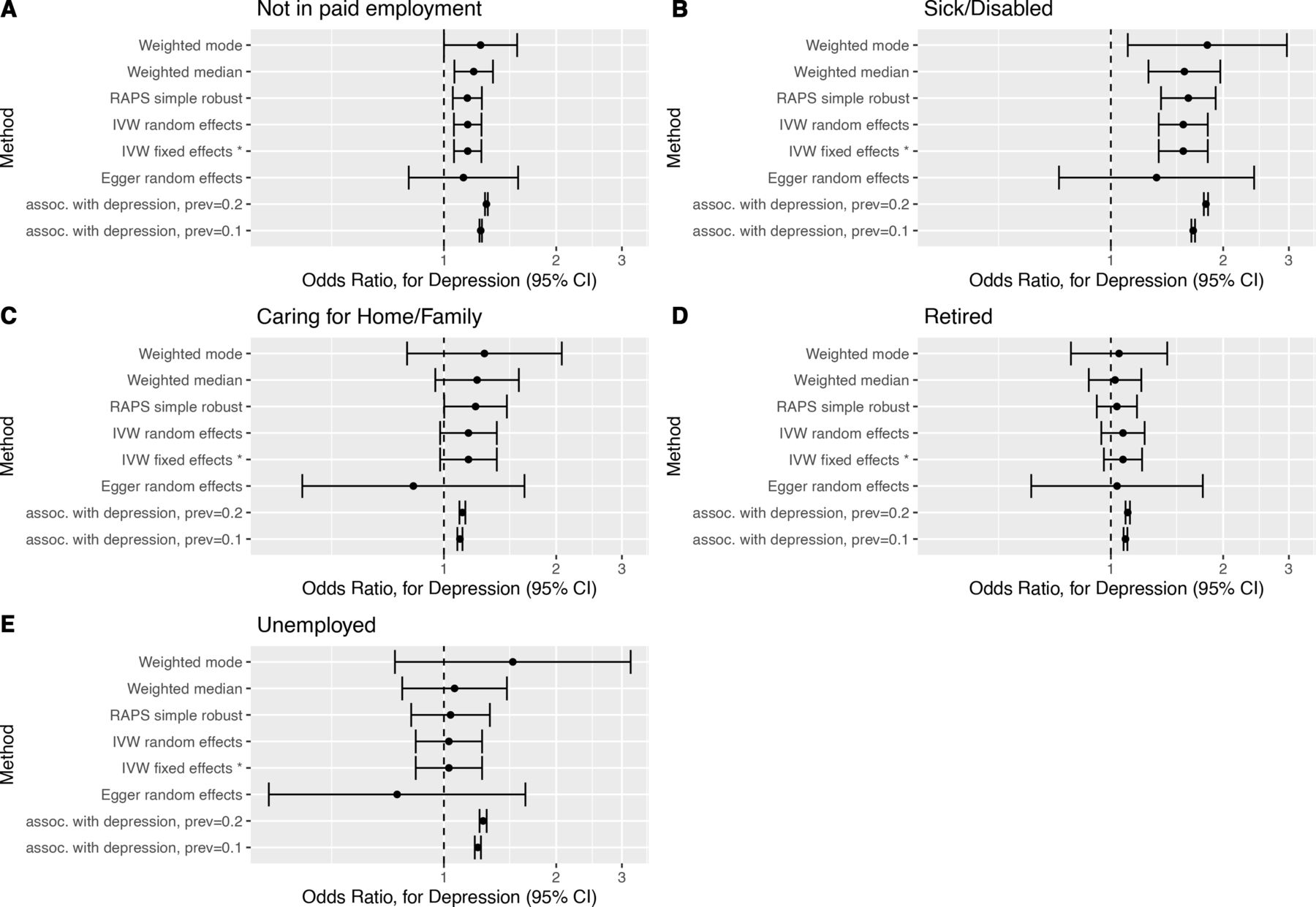
Forest plots of causal effect estimates of depression on employment outcome. Causal effect estimates for change in depression affection status from unaffected to affected on (A) not in paid employment, (B) sick/disabled, (C) caring for home/family, (D) early retirement and (E) unemployment. The association estimates transformed onto the same scale as the Mendelian randomisation estimates are presented in rows prefixed ‘assoc. with depression’, for example, ‘assoc. with depression, prev=0.1’, where prev=0.1 indicates a baseline depression prevalence of 10%. RAPS, Robust Adjusted Profile Score.
Outcomes
The outcomes used were previously described in our paper relating body mass index to employment outcomes.12 All outcomes were obtained at the baseline interview. Current employment status was self-reported, with the five most common categories being (1) ‘in paid employment or self-employed’; (2) retired; (3) sickness/disability (ie, not working due to health); (4) caring for home/family; and (5) unemployed. As the sample only included those of working age, anyone retired was in early retirement. For brevity, we will refer to in paid employment or self-employed as being in paid employment throughout. Employment status was recoded into (1) a binary variable contrasting all other categories (hereafter referred to as non-employment) against being in paid employment and (2) into four binary variables comparing each other category against being in paid employment. Where respondents endorsed multiple categories (<8% participants), ‘employed’ took priority in coding the binary variables. We also considered self-reported weekly hours in paid employment, Townsend Deprivation Index (TDI), household income and highest educational attainment as outcomes. TDI is a measure of area-based deprivation13; greater TDI scores imply greater deprivation. Highest educational attainment was an ordinal variable coding for UK academic qualifications from lowest to highest: (1) none of the below; (2) Certificates of Secondary Education (CSEs) or equivalent; (3) O levels/General Certificates of Secondary Education (GCSEs) or equivalent; (4) A levels/AS levels or equivalent; (5) National Vocational Qualification (NVQ) or Higher National Diploma (HND) or Higher National Certificate (HNC) or equivalent; (6) other professional qualifications, for example, nursing and teaching; and (7) college or university degree. Annual gross household income was coded as an ordinal variable: (1) less than £18 000, (2) £18 000–£30 999, (3) £31 000–£51 999, (4) £52 000–£100 000 and (5) greater than £100 000. Table 1 summarises these outcomes. For details of UK Biobank variables used, see section 2 and online supplemental table S10.
Study sample characteristics
Exposure
A dichotomous indicator variable for depression was created, indicated by a hospital inpatient International Classification of Diseases, 9th Revision (ICD-9), or International Classification of Diseases, 10th Revision (ICD-10), depression diagnosis, self-reported depression or self-report of seeing a psychiatrist for depression, anxiety or tension (see online supplemental section 2). Prevalence of this phenotype in participants was 12.4% and 16.8% in men and women, respectively. This phenotype was used for association analyses and Polygenic Risk Score (PRS) regression. The MR analyses estimates relate to the Howard et al 11 depression phenotype.
Statistical analyses
We generated an unweighted PRS for depression for each participant, calculated as the number of risk alleles carried across all instrument SNPs. To confirm the depression–instrument SNPs relationship in our sample, we regressed depression on PRS adjusting for age, sex, study assessment centre and 40 genetic principal components (GPCs). Inclusion of GPCs (and study centres) as covariates in a regression is a standard way of correcting for confounding between genes and outcomes (population stratification). We used all 40 GPCs, available from UK Biobank, as covariates. Although some GPCs may be redundant, their inclusion does no harm other than reducing power. For details, see online supplemental section 2.
We investigated the multivariable adjusted association of depression with outcomes. Regression models were fitted adjusting for age, sex, study assessment centre and 40 GPCs. For household income, an additional covariate, number in household (values were winsorised to 12), was added to the regression. As this covariate strongly predicted household income, it was carried forward into subsequent MR analyses of household income.
To facilitate comparison of the MR and association study estimates, the estimate for the regression of each outcome on depression was transformed onto the same scale as the MR estimates. Major depression has a prevalence of about 15%, and women are at twice the risk as men. Therefore, depression prevalences of 10% and 20% are appropriate for men and women, respectively.14 These prevalences were used in transforming the association results onto the MR scale. The transformation used is detailed in online supplemental section 2.
We estimated causal relationships via two-sample MR, the inputs for which were SNP–exposure associations (obtained from Howard et al), and SNP–outcome associations (from our sample). SNP–outcome associations were estimated using linear, logistic and ordinal regressions of continuous, binary and ordinal outcomes on each SNP, adjusting for age, sex, study assessment centre, and 40 GPCs (implemented using PLINK V.1.9).15 The MR causal effect estimates obtained gave predicted outcome change in response to depression prevalence increasing by one unit on the log odds scale.16
We estimated the causal effect for depression liability on outcomes using methods available in the R package TwoSampleMR.17 We used the Rücker model selection framework to identify the best fitting model from fixed and random effect versions of the inverse-variance weighted (IVW) and Egger methods.18 19 However, the various methods each have their own strengths and weaknesses and their estimates should be considered together. IVW and Egger methods do not allow for some SNPs being outliers from their respective models. In contrast, the median and mode-based MR methods allow a high proportion of SNPs to be invalid instruments under balanced pleiotropy. The simple median method has a 50% breakdown level; that is, it provides a consistent estimate of the causal effect as long as at least 50% of genetic variants are valid instruments. The weighted median method provides a consistent estimate if >50% of the weight is on valid instruments. It is biased under directional pleiotropy (though not as badly as IVW) because the median effect (even when that of a valid instrument) will tend towards that of the directional pleiotropy SNPs. A penalised median method reduces such bias further.20 Mode methods are similar to the median methods except that the mode of a smoothed approximation of the distribution of SNP causal effect estimates is used in place of the median. The mode method has a higher (though unknown) breakdown level than the median method.21 The Robust Adjusted Profile Score method uses profile likelihood to model weak instruments and balanced pleiotropy, and is robust to idiosyncratic pleiotropy in a small proportion of outliers by capping their influence using a Huber/Tukey loss function.22
To assess potential MR assumption violations, we estimated causal effects using a wide range of MR estimators. We tested for heterogeneity in causal effect estimates and conducted test for unbalanced horizontal pleiotropy. We calculated  , a measure of the degree of violation of the no measurement error (NOME) assumption for SNP–exposure associations.23 To assess whether any single SNP was driving effect estimates, we conducted single SNP MR analyses and leave one SNP out MR analyses. We attempted to repeat analyses with overly influential SNPs removed, but no overly influential SNPs were identified. P values are reported without multiple testing correction.24 Details are provided in online supplemental section 2.
, a measure of the degree of violation of the no measurement error (NOME) assumption for SNP–exposure associations.23 To assess whether any single SNP was driving effect estimates, we conducted single SNP MR analyses and leave one SNP out MR analyses. We attempted to repeat analyses with overly influential SNPs removed, but no overly influential SNPs were identified. P values are reported without multiple testing correction.24 Details are provided in online supplemental section 2.
To investigate sex differences in the impacts of depression, MR analyses were repeated, stratified by sex. Wald tests were used to test for effect size difference between the sexes. The impact of sex on the genetic architecture of depression has been investigated and while modest differences have been found, there is little support for major differences in genetic architecture across sexes.25 We found there was little difference between the sexes in the distribution of the PRS (see table 1). We repeated our depression PRS regression with the addition of a PRS×sex interaction term. The inclusion of the interaction term was not supported (interaction term p value=0.91). In light of these considerations, we decided to use our main MR analysis SNP set for our sex-specific MR analyses, rather than the less powerful sex-specific SNP sets. For further details, see online supplemental section 2.
Results
The sample (see table 1) comprised 230791 genetically unrelated working-age white British participants. The majority (54.5%) were men. Men tended to be older, worked more hours weekly, reported early retirement more frequently and being in paid work and caring for home and family less frequently.
Results for the regression of outcomes on depression are presented in table 2. People who experienced depression had higher odds of reporting not being in paid employment (OR 2.27, 95% CI 2.21 to 2.33) and being in each constituent non-employment category, especially being sick/disabled (OR 6.27, 95% CI 6.02 to 6.53). They also had lower weekly hours in paid employment (−1.09 hours, 95% CI −1.25 to –0.93) and higher TDI (ie, were more deprived) (beta 0.80, 95% CI 0.76 to 0.83). Ordinal regressions found depression associated with reduced household income level (OR 0.53, 95% CI 0.51 to 0.54) and lower educational attainment (OR 0.83, 95% CI 0.81 to 0.85). Results for covariates are shown in online supplemental table S1.
Association of outcomes with depression
The depression OR for each unit increase in PRS was 1.02 (95% CI 1.017 to 1.024). The PRS had a delta Akaike information criterion (AIC) of 133.6 (relative likelihood=9.7e-30), confirming that the instrument SNP set was strongly associated with depression (online supplemental table S2).
Figure 1 plots the SNP–outcome against SNP–exposure associations for the sick/disabled outcome. Consistent with the MR analysis assumptions, SNPs more strongly associated with exposure (depression) were also more strongly associated with the outcome. Similar plots are available for the other outcomes (eg, online supplemental figure S9).
Two sample MR estimates of the causal effect of depression liability on outcomes are presented (1) in table 3 for the estimator selected via the Rücker model selection framework, (2) in figures 2 and 3 as forest plots for a subset of estimators, (3) in online supplemental figures S3–S5 as forest plots for all estimators and (4) in online supplemental tables S3–S5 for all estimators.
{kind=link}
{kind=link}
{kind=link}
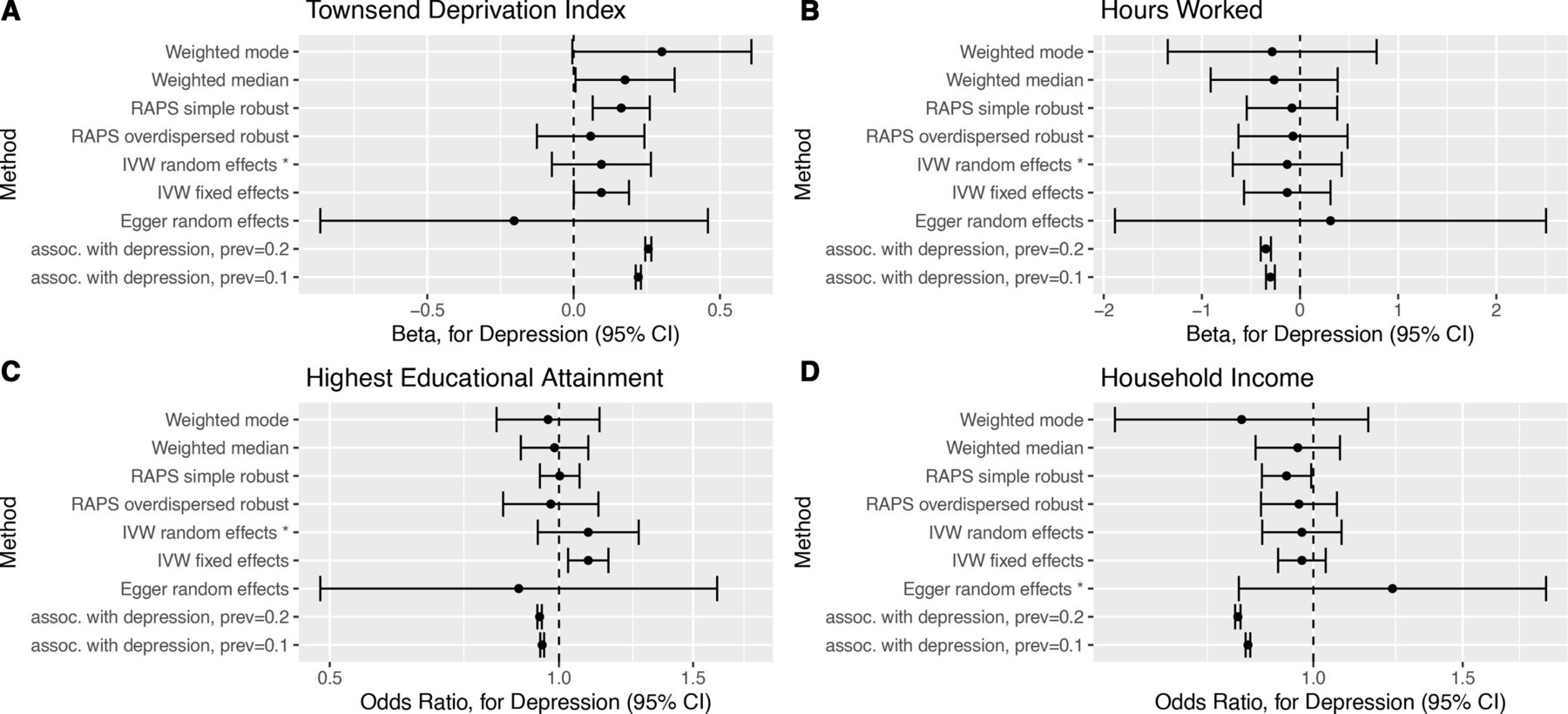
Forest plots of causal effect estimates of depression on other outcomes. Causal effect estimates for change in depression affection status from unaffected to affected on (A) Townsend Deprivation Index, (B) hours worked, (C) highest educational attainment and (D) household income level. The association estimates transformed onto the same scale as the Mendelian randomisation estimates are presented in rows prefixed ‘assoc. with depression’, for example, ‘assoc. with depression, prev=0.1’, where prev=0.1 indicates a baseline depression prevalence of 10%. RAPS, Robust Adjusted Profile Score.
Mendelian randomisation causal effect estimates for depression on employment outcomes
The MR estimates can be directly compared with the transformed association study results (table 2 columns suffixed ‘(MR scale)’ and rows prefixed ‘assoc. with depression’ figures 2 and 3). For several outcomes (not in paid employment, unemployment, TDI, highest educational attainment and household income), the transformed association appeared inconsistent with the Rucker selected MR estimate. This suggests that the association study result was confounded for these outcomes.
The MR estimates indicate that depression liability increased the risk of not being in paid employment (OR 1.16, 95% CI 1.06 to 1.26), and this was attributed to it causing increased risk of sickness/disability (OR 1.56, 95% CI 1.34 to 1.82). The MR analyses provided little evidence (p value >0.05) for an effect on caring for home/family (OR 1.16, 95% CI 0.97 to 1.34), early retirement (OR 1.07, 95% CI 0.96 to 1.21), unemployment (OR 1.03, 95% CI 0.84 to 1.27), hours worked (OR −0.13, 95% CI −0.69 to 0.42), TDI (OR 0.10, 95% CI −0.07 to 0.26), household income (OR 1.24, 95% CI 0.82 to 1.88) or highest educational attainment (OR 1.09, 95% CI 0.94 to 1.27). There was little evidence that depression liability effects differed by sex for any outcomes (online supplemental table S9). Full results are presented in online supplemental section 3.
The robustness of MR estimates was investigated. For each outcome,  was around 0.97 (caution advised if <0.9),23 and so the degree of NOME assumption violation was minor. Heterogeneity tests suggested effect size heterogeneity across SNPs for hours worked, TDI, household income and highest educational attainment (online supplemental table S6). Consequently, fixed-effect estimates and the maximum likelihood estimate may not be reliable for these outcomes. There was little evidence of unbalanced pleiotropy for any outcome (online supplemental table S7). The Rücker model selection framework results coincided with the heterogeneity test results but not with those of the unbalanced pleiotropy tests, in that Egger regression was selected for highest educational attainment (online supplemental table S8, figures S8 and S12). This did not affect the inferences one would draw. Single SNP MR analyses and leave one SNP out MR analyses produced estimates with approximately Gaussian distributions for all outcomes except caring for home/family (eg, online supplemental figures S6 and S10). Thus, single SNPs are unlikely to be driving results except for this outcome. Also, no overly influential SNPs were identified (using Cook’s distance) for any outcome (eg, online supplemental figures S7 and S11). Robustness analyses are detailed in online supplemental section 3.
was around 0.97 (caution advised if <0.9),23 and so the degree of NOME assumption violation was minor. Heterogeneity tests suggested effect size heterogeneity across SNPs for hours worked, TDI, household income and highest educational attainment (online supplemental table S6). Consequently, fixed-effect estimates and the maximum likelihood estimate may not be reliable for these outcomes. There was little evidence of unbalanced pleiotropy for any outcome (online supplemental table S7). The Rücker model selection framework results coincided with the heterogeneity test results but not with those of the unbalanced pleiotropy tests, in that Egger regression was selected for highest educational attainment (online supplemental table S8, figures S8 and S12). This did not affect the inferences one would draw. Single SNP MR analyses and leave one SNP out MR analyses produced estimates with approximately Gaussian distributions for all outcomes except caring for home/family (eg, online supplemental figures S6 and S10). Thus, single SNPs are unlikely to be driving results except for this outcome. Also, no overly influential SNPs were identified (using Cook’s distance) for any outcome (eg, online supplemental figures S7 and S11). Robustness analyses are detailed in online supplemental section 3.
Discussion
We investigated the causal effect of depression liability on employment-related outcomes in the UK Biobank study by using a set of genetic variants robustly associated with depression. Multivariable adjusted regression analyses indicated that people who had suffered depression were more likely to be in non-employment (for any reason) and had greater socioeconomic disadvantage. In contrast, MR analyses suggested that depression liability increased risk of not being in paid employment due to sickness or disability. The MR analyses provided little support for an effect on any other investigated outcome. For about half the outcomes, the regression and MR estimates differed (see figures 2 and 3), suggesting confounding of regression estimates. There was little evidence for depression liability effects on outcomes differing by gender.
The relative importance of health selection and social causation has been investigated with longitudinal observational studies in a range of high-income countries, tending to find stronger evidence for social causation than for health selection.4 5 26 27 The strongest evidence for health selection relates to the transition from adolescence to early adulthood (ie, lower educational attainment transitioning into lower status adult occupations),3 26 28–30 although a meta-analysis of mental health effects on being employed suggested relatively small effects on transitions from schooling to adult employment.4 Our findings did not support an effect of depression liability on education. Regarding health selection operating in later adulthood, several studies show little to no effect,3 26 31 but others show effects of adult depression or psychiatric distress on employment and related outcomes (eg, employability, promotion and contract permanence).3–5 32–34 Our findings support the health selection hypothesis as we identified effects of depression liability on employment. Our study design did not investigate the social causation hypothesis. Social causation could be occurring alongside health selection. Our analyses were not intended to directly support or refute social causation.
Studies making similar assumptions may erroneously support a biased effect estimate. Using different approaches based on different assumptions and biases (triangulation) can increase confidence in findings or highlight assumptions requiring further examination.35 Our study adds to the mixed evidence for effects of depression on socioeconomic disadvantage, giving greater clarity on mechanisms by indicating that depression increases the likelihood of being out of work due to sickness or disability.
Genetic variants are randomly allocated at conception. Consequently, MR is less subject to reverse causation and does not assume no unmeasured exposure–outcome confounding. This is the first study, to our knowledge, to use MR to investigate the effects of depression on reasons for not working. A previous MR study looked at the effect of risk factors (including depression) on social and socioeconomic outcomes in UK Biobank.36 In contrast to our study, they did not find evidence for depression being causal on employment outcomes examined, and they found evidence of depression being causal on reduced household income. Their coding for depression was similar to ours but only covered 10 of the 22 UK Biobank assessment centres; their depression associating SNP set was smaller; and they used a PRS as their instrument, rather than using their SNPs as a set of instruments. This may account for result differences between the two studies. Our findings need to be considered in light of potential limitations. There is a well-known selection bias in the UK Biobank cohort, participants tending to be healthier, wealthier and better educated than the general UK population, consistent with a ‘healthy volunteer’ effect.37 This could result in our findings not generalising. However, UK Biobank risk factor–trait associations have been found to be similar to the UK population when there is reasonable risk factor variation.38 Participant self-selection may have induced collider bias in our findings.39 It has been found that genetic variants are not generally correlated with a broad range of 96 behavioural, socioeconomic and physiological baseline factors and so would be unlikely to be subject to strong selection biases.40 An unfortunate limitation of our study is that it depends heavily on Caucasian genetic data to address a problem that disproportionately affects ethnic minorities. Restricting our analyses to white British participants aged 40–65 means results may not generalise to other ethnicities or early working-age people. While avoiding standard sources of unmeasured confounding, MR is potentially susceptible to confounding by population structure. We minimised this by restricting the sample to those of white British ancestry and adjusting for GPCs plus assessment centre. A similar covariates set has been shown to adequately account for confounding by birth location for some but not all traits.41 Thus, our estimates are as rigorous as we could provide, but some confounding may remain. This is further discussed in online supplemental section 4.42 43Another potential source of bias is dynastic effects, that is, parents with high depression genetic propensity, conferring some unrelated advantage/disadvantage regarding employment to their offspring. Sibling MR analysis, which could address this, would be underpowered in the UK Biobank dataset. Our results refer to the UK labour market, specifically that experienced by an older cohort who have lived through weakening of traditional gender roles, and may not apply to markedly different labour market contexts.
The MR estimates we report are average effects on those from age 40 to 65. It could be that the social mechanisms underlying the effect differs across the age groups studied. Similarly, the effects being estimated may differ for younger age groups (for whom we do not have data) and would likely differ in different social contexts, such as in other countries where different social and cultural norms around paid employment operate. Also, UK Biobank subjects were assessed during a relatively short time frame of 5 years, and age at assessment may correlate with temporal changes in society. Fortunately, age is a covariate in all the regressions, so adjustment has been made for this.
Regarding our MR, we have referred throughout to the effect of depression liability on outcome. When interpreting the MR results, estimates reflect the effect of liability to depression on the outcome. Some people will experience a degree of this latent liability to depression without ever actually experiencing depression, and this liability may affect their outcomes. Therefore, our instrument SNPs do not solely instrument the binary exposure ‘having depression’ but rather the effect of an underlying liability to depression.44
Conclusions
The effect estimates for depression liability on sickness and disability are important, considering the high societal and personal costs of inability to work for health reasons. Depression has high prevalence and can have strong adverse effects on day-to-day functioning for extended periods of time. Consequently, the global burden it imposes is one of the highest for any disorder.45 In Britain, the proportion of sickness and disability-related benefits claimants accounted for by depressive disorders rose from 8.9% in 1995 to 20.6% in 2014 despite little change in claimant numbers.46 Societal costs include workforce absenteeism and presenteeism, suicidality and comorbidities, and their societal consequences. Depression treatment has been well researched, and effective treatments are available.47 Despite this, depression treatment is underfunded worldwide. Return on investment in increased depression treatment has been estimated at approximately 2 to 1 for healthcare and 3 to 1 if indirect costs are included.48
Our finding that depression liability increased sickness/disability risk raises the potential that early intervention through effective healthcare could mitigate the adverse societal impacts of depression by increasing working capacity within the population. It also may inform the development of workplace interventions tailored for individuals with mental health issues, such as individual placement and support.49 Further research is advisable to explore whether this is so and to quantify impact. Evaluations of mental health interventions or policies should consider collecting information on employment-related outcomes, especially being out of work due to sickness/disability.
What is already known on this subject
The relative importance of depression being causal on socioeconomic disadvantage (health selection) and the reverse causal direction (social causation) haves been investigated with longitudinal observational studies in a range of high-income countries.
These have tended to find stronger evidence for social causation than for health selection, for which the evidence is mixed.
What this study adds
We used Mendelian randomisation (a study design different from those used in previous studies) to investigate the health selection hypothesis, specifically, the effect of depression liability on different reasons for not working and on income, education, deprivation and hours worked.
Our findings, relating to working-age people over 40, support an effect of depression on employment (through increased sickness and disability) but not on the other socioeconomic indicators examined.
This may justify government intervention, as improving people’s mental health has potential to reduce adverse employment effects.
Data availability statement
Data may be obtained from a third party and are not publicly available. Access to the dataset upon which this study is based must be sought from UK Biobank. The code used in the study analyses is available upon request from the authors.
Ethics statements
Patient consent for publication
Ethics approval
This study involves human participants and was approved by North West Multi-centre Research Ethics Committee (UK Biobank Research Ethics Committee approval number 11/NW/0382). Participants gave informed consent to participate in the study before taking part. Written informed consent was obtained from all subjects/patients. All procedures contributing to this work comply with the ethical standards of the relevant national and institutional committees on human experimentation and with the Helsinki Declaration of 1975, as revised in 2008.
Acknowledgments
We thank all participants, staff and funders of the UK Biobank study and the NHS staff who collected data provided by patients as part of their care and support.
References
Supplementary materials
Supplementary Data
This web only file has been produced by the BMJ Publishing Group from an electronic file supplied by the author(s) and has not been edited for content.
Footnotes
Twitter @vkatikireddi
Contributors Literature search: SVK, MJG, DC, ND and ED; study design: SVK and MJG; data collection: DMH, AMM and DC; data analysis: DC; data interpretation: SVK, MJG, ND, SH and DC, plus all the other authors; writing: DC, SVK, MJG, ND and SH, plus all other authors; figures and tables: DC. Guarantor: SVK.
Funding This study was conducted using data from the UK Biobank resource (application number 17333). This work is part of a project entitled ‘Social and Eonomic Consequences of Health: Causal Inference Methods and Longitudinal, Intergenerational Data’, which is part of the Health Foundation’s Social and Economic Value of Health Programme (grant ref. 807293). The Health Foundation is an independent charity committed to bringing about better health and health care for people in the UK. This work was further supported by the Medical Research Council (DC, MG, ED and SVK, grant ref. MC_UU_00022/2) and the Scottish Government Chief Scientist Office (DC, MG, ED and SVK, grant ref. SPHSU17), an NHS Research Scotland (NRS) Senior Clinical Fellowship (SVK, grant ref. SCAF/15/02), an Economics and Social Research Council (ESRC) Future Research Leaders grant (NMD, grant ref. ES/N000757/1), a Norwegian Research Council (NMD, grant ref. 295989), a Career Development Award from the UK Medical Research Council (LDH, grant ref. MR/M020894/1), a MRC Strategic Award (ED, grant ref. MRC_PC_13027), a Sir Henry Wellcome Postdoctoral Fellowship (DMH, grant ref. 213674/Z/18/Z), a Brain & Behavior Research Foundation 2018 NARSAD Young Investigator Grant (DMH, grant ref. 27404), the Medical Research Centre Integrative Epidemiology Unit at the University of Bristol (MM, grant ref. MC_UU_0011/1, MC_UU_0011/7), Medical Research Centre grant (AMM, grant ref. MC_PC_17209) and Wellcome Trust grants (AMM, grant ref.s 104036/Z/14/Z, 220857/Z/20/Z).
Competing interests SVK reports grants from the Medical Research Council, the Health Foundation and the Scottish Government Chief Scientist Office during the conduct of this study.
Provenance and peer review Not commissioned; externally peer reviewed.
Supplemental material This content has been supplied by the author(s). It has not been vetted by BMJ Publishing Group Limited (BMJ) and may not have been peer-reviewed. Any opinions or recommendations discussed are solely those of the author(s) and are not endorsed by BMJ. BMJ disclaims all liability and responsibility arising from any reliance placed on the content. Where the content includes any translated material, BMJ does not warrant the accuracy and reliability of the translations (including but not limited to local regulations, clinical guidelines, terminology, drug names and drug dosages), and is not responsible for any error and/or omissions arising from translation and adaptation or otherwise.